“How to make your Google/Nest smart speakers, displays, and cameras listen for suspicious sounds - TechHive” plus 4 more
“How to make your Google/Nest smart speakers, displays, and cameras listen for suspicious sounds - TechHive” plus 4 more |
- How to make your Google/Nest smart speakers, displays, and cameras listen for suspicious sounds - TechHive
- NOAA's Cloud Systems Help Manage Telework Capabilities - MeriTalk
- Google Launches Fully Integrated Google Cloud VMware Engine - Solutions Review
- Facebook's voice synthesis AI generates speech in 500 milliseconds - VentureBeat
- Systemware, Inc. Brings Enhanced Content Services Capabilities to the Cloud With New Platform Update - EnterpriseTalk
| Posted: 15 May 2020 03:00 AM PDT Google just relaunched its Nest Aware home security plans, complete with a simplified pricing structure and a host of new features. Chief among them: the ability for Google smart displays and speakers to alert you if they hear something suspicious. Users who pony up $6 a month ($60 if paid annually) for the standard Nest Aware plan will be able to set their Google Home and Nest devices to detect the sound of breaking glass and smoke alarms. The subscription covers all the Nest devices in your home and includes 30 days of cloud storage for event recordings made by Nest security cameras ("events" are recordings triggered by motion or sound). A $12-per-month/$120-per-year plan gives you 60 days of event storage in the cloud, plus 10 days of 24/7 video recording. It's a nifty feature that essentially turns a dumb smoke detector into a smart one, and it matches the similar (but free) Guard feature for Amazon's Alexa-powered Echo speakers and displays. Turning on Nest Aware's sound detection feature is easy, and there's even a 30-day Nest Aware trial for new users and those moving over from the first-generation Nest Aware service. 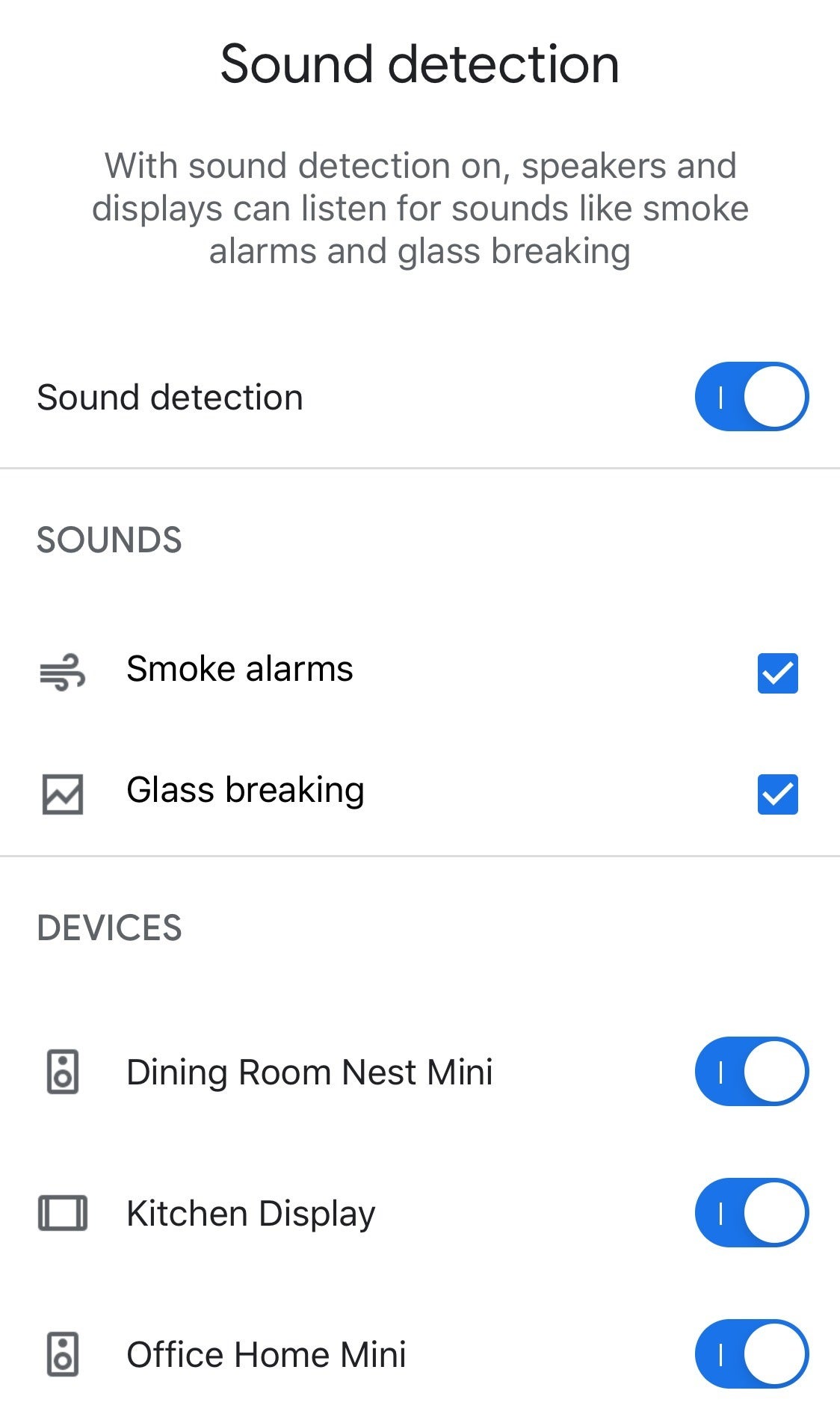 Ben Patterson/IDG Ben Patterson/IDG Using the Google Home app, you can pick which of your Google Home and Nest devices will listen for smoke alarms and breaking glass. How to turn on sound detection for your Google Home or Nest smart device
What will happen when a Google/Nest device hears a suspicious sound
Note: When you purchase something after clicking links in our articles, we may earn a small commission. Read our affiliate link policy for more details. |
| NOAA's Cloud Systems Help Manage Telework Capabilities - MeriTalk Posted: 15 May 2020 07:45 AM PDT The National Oceanic Atmospheric Association (NOAA) has been taking the current remote-standard in stride as it has enough capacity in its cloud-based systems for personnel teleworking. During a webinar event, NOAA CIO Zachary Goldstein spoke about NOAA's readiness and how it followed the General Services Administration's lead back when it set up its cloud system in 2011. Goldstein said that NOAA even ran a test the Thursday before a work-from-home order was put in place for Federal agencies. "When things started looking dicey, and the pandemic was very quickly becoming, not just an item of interest in another country, but [a] clear and present danger to our existence. We did a test on a Thursday, in the D.C.-region had everybody who worked for NOAA in this area go home – if you could," Goldstein said. "There was ample [Virtual Private Network] capacity. The Google Cloud was fine. People were having meetings like this … and it worked pretty well, which was great, because that was a Thursday and the following Monday we had received an order demanding that we telework if possible to do your mission." NOAA was even more so prepared for a pandemic response beyond just the testing of its network capacity, Goldstein said. NOAA's VPN capacity and content operations plan were built with pandemics in mind. "It includes the idea that if you have a pandemic people are going to be sick and other people aren't going to want to come to work so they're going to have to work remotely and that's why we have the capacity," he said. "Going to the cloud, was envisioned in a similar fashion." |
| Google Launches Fully Integrated Google Cloud VMware Engine - Solutions Review Posted: 14 May 2020 12:18 PM PDT
Google is launching its fully integrated VMware migration and support solution Google Cloud VMware Engine, according to a post on the company's blog. The announcement comes almost a year after Google Cloud and VMware announced a partnership to support VMware workloads on the cloud platform. Google Cloud will release the solution into general availability to regions in the U.S. by the end of the quarter; it will then be deployed to global regions in the second half of the calendar year. Our MSP Buyer's Guide contains profiles on the top cloud managed service providers for AWS, Azure, and Google Cloud, as well as questions you should ask vendors and yourself before buying. We also offer an MSP Vendor Map that outlines those vendors in a Venn diagram to make it easy for you to select potential providers. Google Cloud is a cloud provider that delivers IaaS, aPaaS, and PaaS services. Some of the vendor's capabilities include object storage, a Docker container service and event-driven serverless computing. The company has leveraged its internal technology capabilities (automation, containers, networking etc.) by providing a scalable IaaS offering with PaaS capabilities, centered on open-source ecosystems. Google Cloud VMware Engine delivers a fully managed VMware Cloud Foundation stack in a dedicated environment on Google Cloud, including VMware vSphere, vCenter, vSAN, NSX-T, and HCX for cloud migration. Users can now migrate or extend on-premises VMware workloads to Google Cloud in minutes by connecting to a dedicated VMware environment through the Google Cloud Console. The service is designed to minimize operational burden to let users focus on other critical business tasks. In Google Cloud's official blog post, VMware's Senior Vice President and General Manager, Cloud Provider Software Business Unit Ajay Patel stated: "VMware and Google Cloud are working together to help power customers' multi-cloud strategies, and the new Google Cloud VMware Engine will enable our mutual customers to drive digital transformation and business resiliency using the same VMware Cloud Foundation running in their data centers today. Google Cloud VMware Engine enables organizations to quickly deploy their VMware environment in Google Cloud, delivering scale, agility and access to cloud-native services while leveraging the familiarity and investment in VMware tools and training." Learn more about Google Cloud VMware Engine here.  Daniel HeinDan is a tech writer who writes about Enterprise Cloud Strategy and Network Monitoring for Solutions Review. He graduated from Fitchburg State University with a Bachelor's in Professional Writing. You can reach him at dhein@solutionsreview.com Latest posts by Daniel Hein (see all) |
| Facebook's voice synthesis AI generates speech in 500 milliseconds - VentureBeat Posted: 15 May 2020 09:29 AM PDT Facebook today unveiled a highly efficient, AI text-to-speech (TTS) system that can be hosted in real time using regular processors. It's currently powering Portal, the company's brand of smart displays, and it's available as a service for other apps, like VR, internally at Facebook. In tandem with a new data collection approach, which leverages a language model for curation, Facebook says the system — which produces a second of audio in 500 milliseconds — enabled it to create a British-accented voice in six months as opposed to over a year for previous voices. Most modern AI TTS systems require graphics cards, field-programmable gate arrays (FPGAs), or custom-designed AI chips like Google's tensor processing units (TPUs) to run, train, or both. For instance, a recently detailed Google AI system was trained across 32 TPUs in parallel. Synthesizing a single second of humanlike audio can require outputting as many as 24,000 samples — sometimes even more. And this can be expensive; Google's latest-generation TPUs cost between $2.40 and $8 per hour in Google Cloud Platform. TTS systems like Facebook's promise to deliver high-quality voices without the need for specialized hardware. In fact, Facebook says its system attained a 160 times speedup compared with a baseline, making it fit for computationally constrained devices. Here's how it sounds: VB Transform 2020 Online - July 15-17: Join leading AI executives at the AI event of the year. Register today and save 30% off digital access passes. "The system … will play an important role in creating and scaling new voice applications that sound more human and expressive," the company said in a statement. "We're excited to provide higher-quality audio … so that we can more efficiently continue to bring voice interactions to everyone in our community." ComponentsFacebook's system has four parts, each of which focuses on a different aspect of speech: a linguistic front-end, a prosody model, an acoustic model, and a neural vocoder. The front-end converts text into a sequence of linguistic features, such as sentence type and phonemes (units of sound that distinguish one word from another in a language, like p, b, d, and t in the English words pad, pat, bad, and bat). As for the prosody model, it draws on the linguistic features, style, speaker, and language embeddings — i.e., numerical representations that the model can interpret — to predict sentences' speech-level rhythms and their frame-level fundamental frequencies. ("Frame" refers to a window of time, while "frequency" refers to melody.)
 Style embeddings let the system create new voices including "assistant," "soft," "fast," "projected," and "formal" using only a small amount of additional data on top of an existing training set. Only 30 to 60 minutes of data is required for each style, claims Facebook — an order of magnitude less than the "hours" of recordings a similar Amazon TTS system takes to produce new styles. Facebook's acoustic model leverages a conditional architecture to make predictions based on spectral inputs, or specific frequency-based features. This enables it to focus on information packed into neighboring frames and train a lighter and smaller vocoder, which consists of two components. The first is a submodel that upsamples (i.e., expands) the input feature encodings from frame rate (187 predictions per second) to sample rate (24,000 predictions per second). A second submodel similar to DeepMind's WaveRNN speech synthesis algorithm generates audio a sample at a time at a rate of 24,000 samples per second. Performance boostThe vocoder's autoregressive nature — that is, its requirement that samples be synthesized in sequential order — makes real-time voice synthesis a major challenge. Case in point: An early version of the TTS system took 80 seconds to generate just one second of audio. The nature of the neural networks at the heart of the system allowed for optimization, fortunately. All models consist of neurons, which are layered, connected functions. Signals from input data travel from layer to layer and slowly "tune" the output by adjusting the strength (weights) of each connection. Neural networks don't ingest raw pictures, videos, text, or audio, but rather embeddings in the form of multidimensional arrays like scalars (single numbers), vectors (ordered arrays of scalars), and matrices (scalars arranged into one or more columns and one or more rows). A fourth entity type that encapsulates scalars, vectors, and matrices — tensors — adds in descriptions of valid linear transformations (or relations).
 With the help of a tool called TorchScript, Facebook engineers migrated from a training-oriented setup in PyTorch, Facebook's machine learning framework, to a heavily inference-optimized environment. Compiled operators and tensor-level optimizations, including operator fusion and custom operators with approximations for the activation function (mathematical equations that determine the output of a model), led to additional performance gains. Another technique called unstructured model sparsification reduced the TTS system's training inference complexity, achieving 96% unstructured sparsity without degrading audio quality (where 4% of the model's variables, or parameters, are nonzero). Pairing this with optimized sparse matrix operators on the inference model led to a 5 times speed increase. Blockwise sparsification, where nonzero parameters are restricted to blocks of 16-by-1 and stored in contiguous memory blocks, significantly reduced bandwidth utilization and cache usage. Various custom operators helped attain efficient matrix storage and compute, so that compute was proportional to the number of nonzero blocks in the matrix. And knowledge distillation, a compression technique where a small network (called the student) is taught by a larger trained neural network (called the teacher), was used to train the sparse model, with a denser model as the teacher.
 Finally, Facebook engineers distributed heavy operators over multiple processor cores on the same socket, chiefly by enforcing nonzero blocks to be evenly distributed over the parameter matrix during training and segmenting and distributing matrix multiplication among several cores during inference. Data collectionModern commercial speech synthesis systems like Facebook's use data sets that often contain 40,000 sentences or more. To collect sufficient training data, the company's engineers adopted an approach that relies on a corpus of hand-generated speech recordings — utterances — and selects lines from large, unstructured data sets. The data sets are filtered by a language model based on their readability criteria, maximizing the phonetic and prosodic diversity present in the corpus while ensuring the language remains natural and readable. Facebook says this led to fewer annotations and edits for audio recorded by a professional voice actor, as well as improved overall TTS quality; by automatically identifying script lines from a more diverse corpus, the method let engineers scale to new languages rapidly without relying on hand-generated datasets. Future workFacebook next plans to use the TTS system and data collection method to add more accents, dialogues, and languages beyond French, German, Italian, and Spanish to its portfolio. It's also focusing on making the system even more light and efficient than it is currently so that it can run on smaller devices, and it's exploring features to make Portal's voice respond with different speaking styles based on context. Last year, Facebook machine learning engineer Parthath Shah told The Telegraph the company was developing technology capable of detecting people's emotions through voice, preliminarily by having employees and paid volunteers re-enact conversations. Facebook later disputed this report, but the seed of the idea appears to have germinated internally. In early 2019, company researchers published a paper on the topic of producing different contextual voice styles, as well as a paper that explores the idea of building expressive text-to-speech via a technique called join style analysis. Here's a sample: "For example, when you're rushing out the door in the morning and need to know the time, your assistant would match your hurried pace," Facebook proposed. "When you're in a quiet place and you're speaking softly, your AI assistant would reply to you in a quiet voice. And later, when it gets noisy in the kitchen, your assistant would switch to a projected voice so you can hear the call from your mom." It's a step in the direction toward what Amazon accomplished with Whisper Mode, an Alexa feature that responds to whispered speech by whispering back. Amazon's assistant also recently gained the ability to detect frustration in a customer's voice as a result of a mistake it made, and apologetically offer an alternative action (i.e., offer to play a different song) — the fruit of emotion recognition and voice synthesis research begun as far back as 2017. Beyond Amazon, which offers a range of speaking styles (including a "newscaster" style) in Alexa and its Amazon Polly cloud TTS service, Microsoft recently rolled out new voices in several languages within Azure Cognitive Services. Among them are emotion styles like cheerfulness, empathy, and lyrical, which can be adjusted to express different emotions to fit a given context. "All these advancements are part of our broader efforts in making systems capable of nuanced, natural speech that fits the content and the situation," said Facebook. "When combined with our cutting-edge research in empathy and conversational AI, this work will play an important role in building truly intelligent, human-level AI assistants for everyone." |
| Posted: 15 May 2020 05:34 AM PDT  Systemware, Inc., an industry pioneer in enterprise content management, has announced the release and availability of Content Cloud 7.1. Content Cloud is an innovative content services platform that intelligently manages critical business information for many of the world's largest organizations. IT Security- 97% of Enterprises Have Suspicious Activity in Network Traffic This latest update to Content Cloud includes new containerized and scripted deployment options, multifactor authentication, and personalized multilingual UI options. In addition, simplified scaling capabilities utilizing node sets enable organizations to deploy Content Cloud seamlessly in external cloud platforms such as AWS, Microsoft Azure, IBM Cloud, Google Cloud, and more. Content Cloud 7.1 delivers optimized performance in public, private, or hybrid cloud environments, as well as a fully hosted SaaS offering. "From our beginning, Systemware has always been about providing our customers with powerful yet flexible software," says Pat Sheehan, Vice President of Development at Systemware. "Content Cloud 7.1 expands on this flexibility, allowing our customers to have the exact amount of processing power they need, right when they need it. New nodes can deploy in a matter of minutes, satisfying processing needs while offering increased horizontal scalability for better redundancy and failover." The underlying architecture for Systemware Content Cloud 7.1 has been enhanced from the ground up, offering support for Docker containers using the open-source Kubernetes orchestration platform. "By including support for Docker containers and scripted implementation, Systemware Content Cloud 7.1 offers a rapidly scalable infrastructure that is built and optimized for cloud deployments," explains David Basso, Vice President of Sales and Marketing at Systemware. "Content Cloud 7.1 offers industry-leading content indexing, search, and management capabilities in a way that is easier to implement and scale while offering the security and customization options that our customers expect." Nearly 30% of Ransomware Attacks Occur on the Weekend As part of a full suite of security capabilities, Content Cloud 7.1 includes support for TLS encrypted communication between all nodes to support a growing and ever-changing regulatory compliance landscape. Systemware's advanced compliance features provide secure encryption for content while in transit and at rest, data masking for access and display of sensitive information, event-based retention, and a wide range of robust user and group administration capabilities. |




| You are subscribed to email updates from "google cloud event" - Google News. To stop receiving these emails, you may unsubscribe now. | Email delivery powered by Google |
| Google, 1600 Amphitheatre Parkway, Mountain View, CA 94043, United States | |
Comments
Post a Comment